부스팅은 순차적으로 학습-예측하며 잘못 예측한 이전 모델의 데이터에
가중치를 부여해서 학습하는 방식

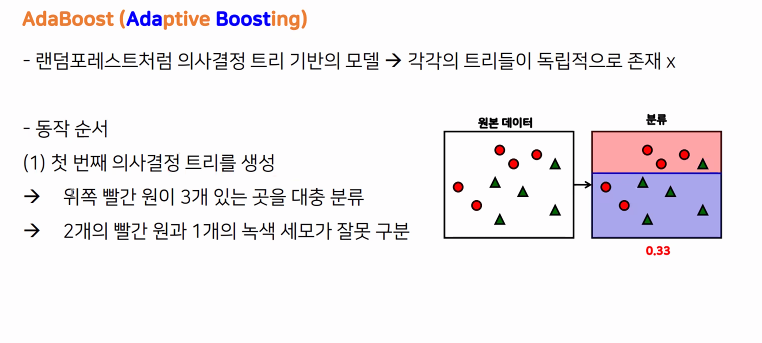


이렇게 분류가 진행된 것들을 결합하는 방식이다

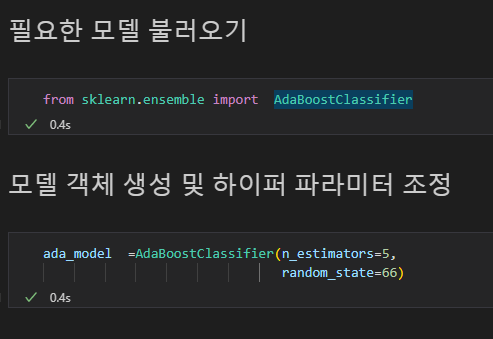
from sklearn.ensemble import AdaBoostClassifier
로 AdaBoost 모델 불러오기
모델명 = AdaBoostClassifier(n_estimators = ?, random_state = 아무숫자)
로 모델 객체 생성하기
하이퍼 파라미터인 n_estimators


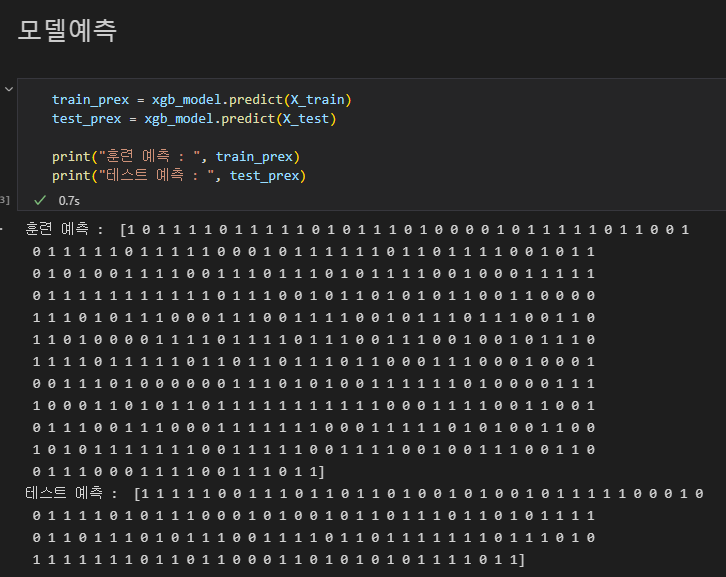
학습 :
모델.fit(훈련용 문제, 훈련용 답)
예측 :
모델.predict(테스트 문제)
평가 :
accuracy_score(테스트용 답, 예측값)

모델명 = 모델종류Classifier ( 하이퍼파라미터 =? ,random_state=아무숫자)

(진행 순서)
1. GridSearchCv 도구를 불러온 후 튜닝할 매개변수 경우의 수 설정
( = 하이퍼 파라미터 경우의 수 설정하기)
2. 사용할 모델 선정, 모델 객체 생성
3. 해당 모델에 GridSearch 설정 연결후 실행하기
4. 최적의 하이퍼 파라미터 확인, 최적의 정확도 확인
5. 최적의 파라미터 조합으로 모델링하기
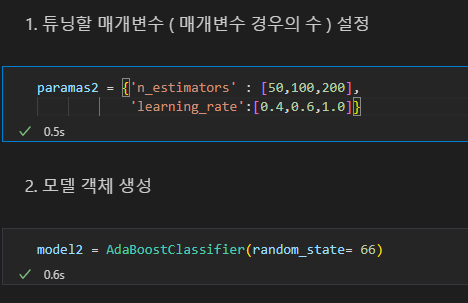
n_estimators : 결정트리의 개수 / 많아지면 성능은 좋아지나 시간이 오래 걸림 / default 값 : 10 /
learning_rate : 순차적으로 진행할때 마다 적용하는 학습률 0~1 /
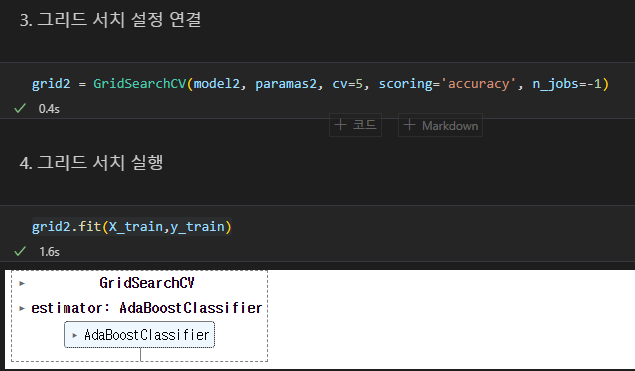
GridSearchCV(대상모델명, 매개변수(하이퍼 파라미터 경우의 수), cv = 교차검증 횟수, scoring = 'accuracy', n_jobs = -1)
으로 그리드 서치 설정 연결
그리드변수명.fit(훈련용 문제, 훈련용답)으로 실행

*.best_변수명_
을 통해
파라미터 경우의 수 변수명을 넣을 경우 최적의 하이퍼 파라미터를,
위에서 accuracy로 넣어준 정확도 변수명을 넣을경우 최적의 정확도를 확인
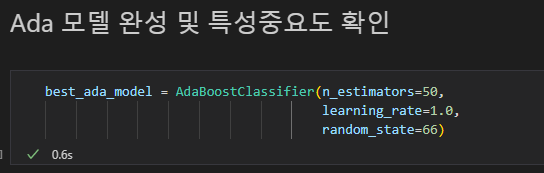
최적 하이퍼 파라미터로 모델객체 재생성

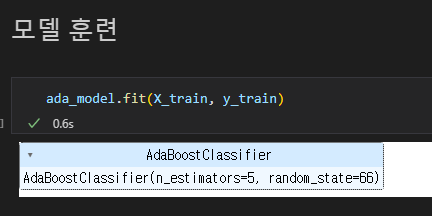
학습 :
모델.fit(훈련용 문제, 훈련용 답)

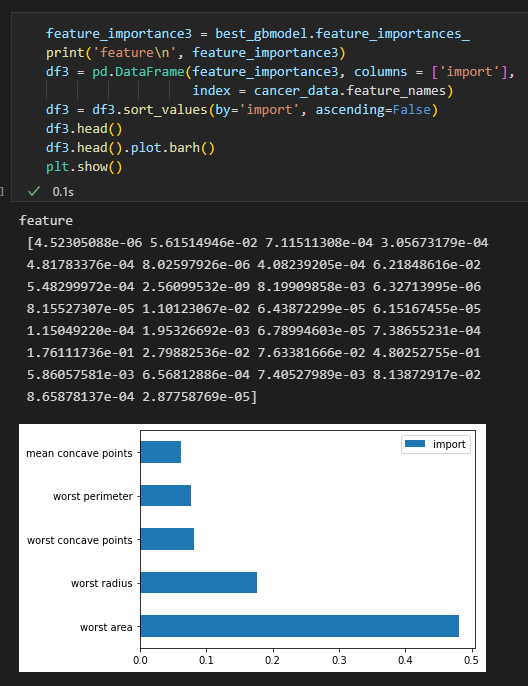
각 피처의 중요도를 확인하는 feature_importance
모델명.feature_importances_
로 확인가능
====================================================

Gradient Boost Machine
AdaBoost와 유사하지만 가중치 업데이트를경사하강법(Gradient Descent)를 이용
예측성능이 높지만 과적합이 빠르게되고 시간이 오래걸림

==================================================

트리 기반의 알고리즘으로 뛰어난 예측성능을 지님
GBM에 기반했으나 GMB의 단점인 느린 수행시간을 해결하고 과적합을 방지하는 규제등이 포함됨
결손값을 자체처리하며 max_depth를 최대깊이까지 분할한후 긍정이득이 없는 가지를 쳐냄
교차검증이 내장되어 지정된 횟수가 아니라 최적화되면 반복을 멈출수있는 기능이 있음 ( early_stoppings )

환경도구 불러오기:
pip install xgboost
import xgboost
from xgboost import XGBClassifier
객체생성하기:
xgb_model = XGBClassifier(파라미터들, random_state = 아무숫자)
학습, 예측:
xgb_model.fit(X_train, y_train)
pre = xgb_model.predict(테스트셋 문제데이터)
GridSearchCV를 사용할 경우:
from sklearn.model_selection import GridSearchCV
paramas = { 파라미터1 = [ 값1, 값2, ... ], 파라미터2 = [ 값1, 값2, ... ] ... }
Xgb_model = XGBClassifier( randim_state = 아무숫자 )
grid = GridSearchCV ( Xgb_model, paramas, cv = 횟수, scoroin = 평가지표, n_jobs = -1 )
grid.fit( 훈련셋 문제, 훈련셋 답, early_stopping_rounds=조기종료 횟수, eval_metric='auc', eval_set=[(X_val, y_val)])