

장점 : DecisionTree의 쉽고 직관적인 장점을 그대로 지님 / 수행속도가 빠름 / 다양한 분야에서 사용가능 (대체적으로 좋은 성능)
다양한 트리를 만드는 방법 = 부트스트랩
배깅은 같은 알고리즘에 대해 데이터 셋을 다르게 두고 각각 학습 (병렬적)
여러 알고리즘이 순차적으로 학습
먼저 학습한 알고리즘 예측이 잘못된 데이터에 대해
다음 순서엔 데이터에 가중치를 부여하여
새롭게 생성된 데이터세과 모델로 학습과 예측을 진행하는 방식


from sklearn.model_selection import train_test_split
훈련셋과 테스트셋의 비율을 나눠주는 도구 train_test_split

유방암 데이터를 로드한 결과

딕셔너리 key 값을 불러오는 *.keys( )
value 값을 불러올땐 *.values( )
둘다 불러올땐 *.items( )

array 형태의 numpy 데이터

○ ndarray 객체 속성 확인하기
배열명.shape -->> 배열 크기 (1차원은 데이터 개수, 2차원은 행열 개수)
배열명.size -->> 내부 데이터 개수
배열명.ndim -->> 몇 차원인지
배열명.dtype -->> 무슨 타입인지(int등)



ndarray 객체
배열명.size -->> 내부 데이터 개수




훈련셋과 테스트셋의 비율을 나눠주는 도구 train_test_split
나눠줄 값 들 여러가지 = train_test_split(문제, 답, test_size=비율, random_state=아무숫자나)

랜덤 포레스트의 하이퍼 파라미터 : n_estimators 등이 있다

from sklearn.ensemble import RandomForestClassifier
으로 랜덤포레트스 불러오기
RandomForestClassifier 의 하이퍼 파라미터는 n_estimators등등

학습 :
모델.fit(훈련용 문제, 훈련용 답)
예측 :
모델.predict(테스트 문제)
평가 :
accuracy_score(테스트용 답, 예측값)

from sklearn.model_selection import cross_val_score
으로 불러온다.
모델의 성능을 평가하는데 사용하며
cross_val_score(검증할 모델명, X, y, cv = 교차 검증시킬 횟수)
형식으로 사용한다.
해댕 결과에 .mean( )를 붙여주면 교차검증 결과의 평균값이 출력된다

from sklearn.metrics import accuracy_score
로 정확도 측정도구인 accuracy_score를 불러온다
accuracy_score(정답, 예측한 값)
의 방식으로 사용한다

(진행 순서)
1. GridSearchCv 도구를 불러온 후 튜닝할 매개변수 경우의 수 설정
( = 하이퍼 파라미터 경우의 수 설정하기)
2. 사용할 모델 선정, 모델 객체 생성
3. 해당 모델에 GridSearch 설정 연결후 실행하기
4. 최적의 하이퍼 파라미터 확인, 최적의 정확도 확인
5. 최적의 파라미터 조합으로 모델링하기
from sklearn.model_selection import GridSearchCV
으로 GridSearchCv 도구 불러오기
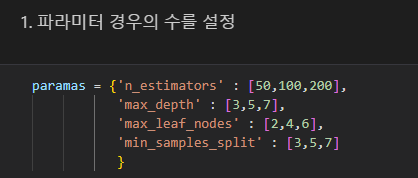
파라미터 경우의 수를 저장한 변수명
paramas = { 'n_estimators' : [50, 100, 200],
'max_depth' : [3, 5, 7],
'max_leaf_nodes' : [2, 4, 6],
'min_samples_split' : [3, 5, 7]
}
n_estimators : 결정트리의 개수 / 많아지면 성능은 좋아지나 시간이 오래 걸림 / default 값 : 10 /
max_depth : 트리의 최대 깊이 / 너무 깊어지면 과적합, 제어필요 /
max_depth : 리프노드 최대 개수
min_samples_split : 노드 분할을 위한 최소 데이터 수 / 과적합 제어에 사용 / 작을수록 분할하는 노드가 많아져 과적합

모델변수명 = 사용할모델Classifier( )
으로 GridSearchCV를 적용할 모델을 선정하고
GridSearchCV(대상모델명, 하이퍼 파라미터 매개변수, cv = 교차검증 횟수, scoring = 'accuracy', n_jobs = -1)
으로 해당 모델에 그리드서치를 설정한다

이후
그리드변수명.fit(훈련용 문제, 훈련용답)으로 학습시킨다
학습 :
모델.fit(훈련용 문제, 훈련용 답)
예측 :
모델.predict(테스트 문제)
평가 :
accuracy_score(테스트용 답, 예측값)

*.best_변수명_
을 통해
파라미터 경우의 수 변수명을 넣을 경우 최적의 하이퍼 파라미터를,
위에서 accuracy로 넣어준 정확도 변수명을 넣을경우 최적의 정확도를 확인가능하다

최적의 파라미터 조합하기 위해 다시 모델 객체를 생성

학습시키면 완성

각 피처의 중요도를 확인하는 feature_importance
모델명.feature_importances_
로 확인가능
해당 피처를 시각화해주면 된다

DataFrame 생성
변수명 = pd.DataFrame(data, columns = ?, index = ?)
이런식으로 DataFrame을 생성!
sort_values : 값을 기준으로 정렬
ascending를 이용해서 정렬순서를 변경하며 by ='정렬 기준'




