ㅇ Dataframe
-- 생성하기
변수 생성
data =[ [a],[b]... ]
col = ['c','d'...]
ind = ['e','f'...]
DataFrame 생성
data= pd.DataFrame(data, columns=col, index=ind)
이런식으로 DataFrame을 생성!
인덱스 생성, 컬럼 생성
변수명.index = ['a','b',...] -->> 인덱스(열)에 이름 생성하기!
변수명.index -->> 인덱스만 확인하기
변수명.columns -->> 컬럼값만 확인하기
변수명.T -->> 전치하기 (Transpose)
응용해서
변수명.columns = ['col1', 'col2']
이런식으로 컬렴명, 인덱스명 설정이 가능함
===============================================================
파일 불러오기 :
file = open('파일명', encoding='UTF-8')
csv 파일 형태 불러오기 :
data = pd.read_csv('파일명', encoding = 'UTF-8')
엑셀파일 형태 불러오기 :
data = pd.read_excel('파일명', encoding = 'UTF-8')
이 방식으로 읽어지지 않을때는
pd.read_excel('파일명', engine = 'openpyxl')
엑셀파일 sheet 지정해서 불러오기 :
import openpyxl
data = pd.read_excel('파일명', sheet_name = 인덱스번호, engine = 'openpyxl')
>> sheet1의 인덱스는 0, sheet2의 인덱스는 1
url로 json 파일 (api등) 불러오기 :
import json
import requests
key = '인증키'
url = f ' http://~주소~ {key} ' 등으로 url과 인증키등을 설정하고
data명 = requests.get(url변수명).json()
혹은
import json
import urllib.requests
data명 = urllib.requests.urlopen(url변수명).read()
data명 = json.loads(data명)
파일을 불러왔을때 컬럼이 많아 ...으로 생략되서 뜰 경우 :
pd.set_option('display.max_columns', None)
컬럼 최대개수 설정
pd.set_option('display.max_colwidth', None)
컬럼 너비 설정
pd.set_option('display.max_rows', None)
행 최대개수 설정
이런식으로 설정을 바꿔준다
===============================================================
- 내부 데이터 확인할때
data명.info()
: 데이터의 총 건 / 타입 / 결측치 / 전체적인 정보 등을 확인한다
-> 컬럼들이 가지고 있는 row의 값이 같은지, non-null인지 등을 통해 결측치 확인
data명.describe()
: 컬럼별 숫자데이터 통계 출력됨
( count 총계, top 가장 많이 나온 요소, min 최소값, mean 평균, max 최대값, freq-top의 횟수 등등의 통계량)
(object형은 출력에서 제외됨)
data명.shape
: 데이터의 행, 열 크기를 튜플로 리턴함
Series명.value_counts()
: 특정 컬럼의 데이터 갯수를 리턴함 / 각각의 value가 몇개씩 들어있는지 /
-> numpy에서는 np.bincount(data명)
(1차원 Series 형태에만 사용 가능 >>
따라서 df형자료형의 컬럼 하나를 불러와서 사용한다)
data명.head(숫자) : 상위 n개의 row 확인하기
data명.columns : df의 컬럼명 모두 출력
data명.values: df의 값만 확인, numpy array 객체로 리턴됨
data명.index : df의 index 모두 출력. ndarray 1차원과 같은 형태로 리턴됨.
data명.unique()
: 해당 컬럼 내부의 유일한 값을 확인 가능하다
결측치는 fillna(채울 값)로 채워주기
===============================================================
-- 인덱싱, 슬라이싱, boolean 인덱싱
DataFrame에서 행은 인덱싱(하나만 뽑아오기)가 안됨. 슬라이싱만 됨!
df변수명['컬럼명']
: 특정 컬럼에 해당하는 데이터 조회
df변수명[ ['컬럼1','컬럼2','컬럼3'] ]
: 여러 컬럼 조회할때는 리스트 객체를 사용함
df변수명[조건식]
: 해당 조건에 맞는 데이터를 불러올때 사용
(ex) data[data['컬럼명1'==3]]
>> data 컬럼명1에서 row값이 3인 데이터들을 리턴
iloc 인덱싱
df변수명.iloc[ 행 index, 열 index ]
iloc 슬라이싱
df변수명.iloc[ 행 시작번호 : 행 끝번호+1 , 열 시작번호 : 열 끝번호+1 ]
loc 인덱싱
df명.loc[ row index 번호, 'column명' ]
boolean 인덱싱
df명[ ] , df명.loc[ ]안에 조건을 넣어 사용가능함
(주의) iloc에서는 사용불가능!
변수명.['a'] -->>
이렇게 a라는 열을 가져오면 Series로 나옴 (하나 가져왔으니까)-->>
2차원으로 보고싶으면 변수명.[['a']]으로 대괄호 안에 넣어주면 됨
===============================================================
-- 정렬
변수명.sort_index()
: 인덱스 기준으로 정렬
df변수 = df변수.sort_values( by = [ '특정컬럼명' ], ascending = True, inplace = False)
: by를 이용하여 특정 컬럼을 기준으로 정렬
여러컬럼이 기준일땐 by = [ '컬럼1' ,컬럼2' ]
이렇게 리스트 형식으로 컬럼명 입력
ascending 이 True일 경우 오름차순 / False 일 경우 내림차순
inplace 가 False일 경우 원본 데이터 유지 / True일경우 원본데이터 정렬
numpy에서는 np.sort(data) 방식을 사용한다
===============================================================
-- 추가, 삭제
변수명['추가할 열'] = [추가할 값]
-->>열 추가
컬럼 삭제하기
df변수명.drop(labels=None, axis=0, inplace = False)
labels : 삭제할 컬럼명. 여러개를 지울때는 리스트형태로 가능
axis : default값이 가로단위 처리로 된 상태. axis=0 >> row를 삭제함
행을 삭제하고싶으면 axis=1이라는 파라미터를 추가해줘야 함
axis = 0 -->> 가로 단위 처리 (row 삭제) // axis = 1 -->> 세로 단위 처리 (column 삭제)
inplace : dafault값은 False. 원본데이터는 삭제하지 않음. 원본을 삭제하려면 inplace = True로 넣어줘야 한다.
===============================================================
-- 이름변경
일부 변경
df.rename(columns = {'변경 전 이름' : '변경할 이름'}, inplace=True)
df.rename(index = {변경전} : {변경할 이름}, inplace=True)
전체 변경
df.columns = [ '변경할 이름1', '변경할 이름2', '변경할 이름3' ...]
인덱스 변경
df.set_index('인덱스로 바꿀 컬럼명', inplace = True)
===============================================================
-- 컬럼 순서 변경

DataFrame = DataFrame[['컬럼3', ' 컬럼2', '컬럼1]]
기존 컬럼 순서가 컬럼1, 컬럼2, 컬럼3이었다 가정하고
이렇게 재선언해주면 순서가 바뀜
===============================================================
-- numpy의 ndarray객체 , list 객체 DataFrame으로 변경하기
list = [1, 2, 3]
array = np.array(list)
>>
df = pd.DataFrame(list1)
df = pd.DataFrame(array)
-- 딕셔너리 객체 DataFrame으로 변경하기
key 값이 columns 이름으로, value 값이 row 값으로 전환됨
dict = { 'name' : [ '채수민', '최영화' ] , 'sex' : [ 'female', 'female' ], 'num' : np.array( [ 1, 2 ] ) }
df = pd.DataFrame(dict, index = ['담임', '부담임'])

-- DataFrame 객체를 numpy의 ndarray, list, 딕셔너리로 변환
딕셔너리 객체로 변환
:df.to_dict('list')
넘파이 객체로 변환
: df.to_numpy()
: df.values
리스트로 변환
: 넘파이 객체로 바꾼후
np.tolist()
=================================================================
-- apply 함수
def 함수명(i)
return 조건식
로 생성한 후 apply(함수명)으로 불러오기 가능
=================================================================
-- 카테고리
데이터, 범주 -->> bins = ['범위지정값','',...], 범주명칭 -->> 범주변수명=['','',...]
=================================================================
-- 데이터프레임 결합하기 (넘파이에선 np.concantenate)
pd.concat([df1, df2]) >> row 합치기
pd.concat([df1, df2], axis = 1 ) >> column 합치기
=================================================================
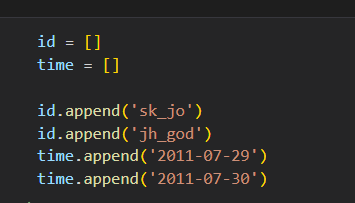
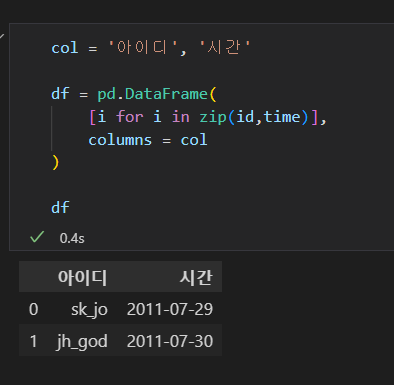
-- 리스트 여러개 zip과 리스트 컴프리핸션으로 DataFrame 만들기
=================================================================




