import requests as rq
from bs4 import BeautifulSoup as bs
url="주소"
res = rq.get(url)
res.text
soup = bs(res.text, "lxml")
soup=bs(driver.page_source, "lxml")
-->>인터넷 드라이버 값을 가져올떄(셀레니움등)
--------------BeautifulSoup로 값 가져올때-------------------------
soup.select("가져올 값")
a= soup.select("가져올 값")
b=soup.select("가져올 값")
a_list=[]
b_list=[]
for i in range(len(a)) :
a_list.append(a[i].text.strip())
b_list.append(a[i].text.strip())
(인덱스 번호 줄경우 인덱스 리스트도 만들어서 i+1로 번호 넣어주기)
index_list=[]
a_list=[]
for i in range(len(a)) :
index_list.append(i+1)
a_list.append(a[i].text.strip())
이런식으로!!
--------------Selenium으로 값 가져올때-------------------------
a_list =[]
index_list=[]
for i in range(범위):
a=driver.find_elements(By.XPATH, '~~경로~~'+str[i]+'~~경로~~' )[0].text
a_list.append(air)
index_list.append(i+1)
==>> for문으로 반복시킬 중복되는 XPATH 경로값에 i 가 들어가므로
위와 다르게 [0].text로 가져온것!!!!
import pandas as pd
dic= {'a' : a_list , 'b' : b_list, 'c' : index_list}
result= pd.DataFrame(dic)
result.set_index('c', inplace=True)
result.to_csv('제목.csv', encoding='EUC-KR')





-->> element(요소)에서 태그를 제외한 컨텐츠만 가져오는 작업
요소 = 태그 + 컨텐츠
--------------------------------------------------------------------------------
# 태그에서 가져올 값이 아이디인지, 클래스인지?
soup.select(태그#아이디)
soup.select(태그.클래스)
원하는 값이 나오지않을 경우 계속 상위로 올라가서 값을 가져와 봐야함
+
데이터의 길이가 정해진 경우 (ex) 멜론Top 100
len()로 list형태의 데이터값을 길이 확인해보기
-------------------------------------------------------------
# DataFrame화 한후 저장하기
위에서 title_list와 singer_list라는 리스트를 만들었다고 가정하면
import pandas ad pd
dic= {'제목' : title_list , '가수' : singer_list}
이런식으로 딕셔너리를 만든후
result= pd.DataFrame(dic)
으로 데이터프레임화 한다
이 result를
result.to_csv('제목.csv', encoding='EUC-KR')
로 csv파일로 만들어 저장해준다
-------------------------------------------------------------
# text 화 시킨 값에 이상한 문자가 있을경우 ??? strip() !!!
a = soup.select(태그.클래스).text로 가져왔는데
값이
\n '헤어질 결심' \w
이런식으로 이상하게 뜰 경우
여러 문자열 출력 특수효과를 지워주는 역할을 하는 strip() 함수를 뒤에 붙여준다!
----------------------------------------------------------------
데이터 가져오는 방법
1. 원하는 부분 > 검사 > 개발자도구에서 확인
2. 개발자 도구 > 포인터클릭 > 원하는 부분 클릭
----------------------------------------------------------------
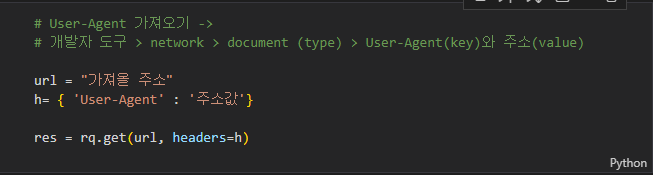
우회작업이 필요한 경우
response[200]이 떠야 정상인데 [400]대 오류가 뜰 경우
서버자체에서 코드 접근을 막아논 상태일 수 있음
이때는 다른 접근 방식이 필요함
h={'User-Agent' : '주소값'}
res = rq.get(url, headers=h)
'Crawling > 기타' 카테고리의 다른 글
| Selenium 라이브러리 오류 모음 (0) | 2022.07.19 |
|---|---|
| replace()와 strip를 섞어서 Crawling한 값 txt파일로 가져오기 (0) | 2022.07.06 |
| Selenium(셀레니움)에서 Element(요소)에 접근하는 방법들 - ( By.XPATH / By.CLASS_NAME / By.ID / By.NAME / By.TAG_NAME / By.LINK_TEXT ) (0) | 2022.07.04 |
| Selenium (셀레니움) 설치하기 및 기본 명령어 / 크롬드라이버 자동설치 (0) | 2022.07.04 |
