Machine Learning/회귀모델
Linear Regression (선형회귀모델) 실습 [ 회귀성능지표의 종류 / 특성확장으로 과적합 제어 및 모델성능 향상 ] [ 보스턴 데이터 ]
leehii
2022. 8. 11. 17:12

bunch 번치 타입 객체 : 딕셔너리 형태
keys / items / values로 불러오기 가능
dict.keys()로 key값 확인
'data'라는 key 값으로 value 값 불러오기 (numpy array 형태)
마찬가지로 피쳐 이름 확인
그냥 인덱싱해왔을 경우 \n 등이 그대로 나오므로 print해줌

target 답 데이터 확인
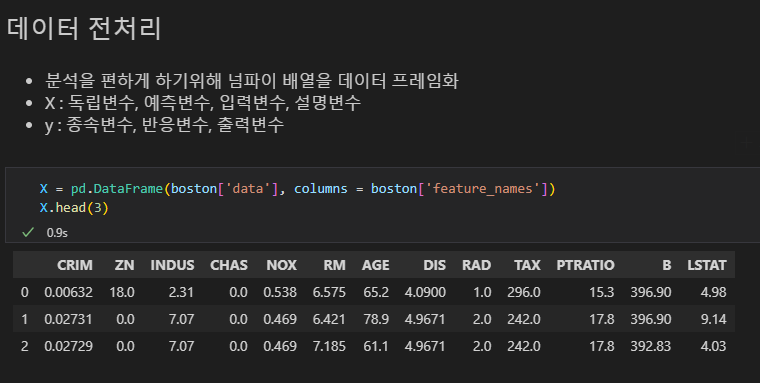

numpy array 자료나 list형 자료는 그대로 DataFrame화 할 수 있음 (컬럼명은 필요)
X 문제 데이터의 컬럼명은 feature_name라는 key값이 있었으므로 연결해줌
정답은 target 한개므로 Series 데이터로 만들어줌

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split ( X, y, train_size = 0,7, ransom+state = 아무숫자 )
df.shape
: 데이터의 행, 열 크기를 튜플로 리턴함

선형회귀모델 Linear Regression
from sklearn.linear_model import LinearRegression
교차검증으로 모델 일반화성능을 확인하는 cross_val_score
model.fit(테스트용 문제, 테스트용 답)
으로 학습

model.predict(테스트문제)
>> 답을 예측할 순 없다는걸 생각하기
>> 그럼 문제를 보고 답을 예측해야하는데
>> train셋은 훈련시키는 용이므로 예측할때 쓰는건 test 셋
교차검을으로 모델 일반화를 확인하는 cross_val_score
cross_val_score(model명, 학습용문제, 학습용답, cv = 교차검증 횟수)
>> 교차검증을 통해 모델 일반화를 확인하는것
>> 당연히 학습, 훈련을 담당하는 train 셋 데이터를 사용해야함
대략 71%의 평균값을 지님

회귀의 평가를 위한 지표는 실제 값과 회귀 예측값의 차이를 기반으로 힘
mse : 평균제곱오차
rmse : 제곱근 평균제곱오차
mae : 예측값 - 실제값을 제곱하지 않고 평균을 낸것
r2 : 분석기반 예측 성능 평가

sklearm.metrics 모듈이 성능평가를 담당함
from sklearn.metrics import mean_squared_error
mse : 평균제곱오차
from sklearn.metrics import mean_absolute_error
mae : 평균절대오차
from sklearn.metrics import r2_scorer
r2_score : 결정계수, R-Squared

mean_squared_error(y_test, pre)
평균 제곱 오차
np.sqrt(mean_squared_error(y_test, pre))
제곱근 평균 제곱 오차
mean_absolute_error(y_test, pre)
평균 절대 오차
r2_score(y_test, pre)
R-Squared


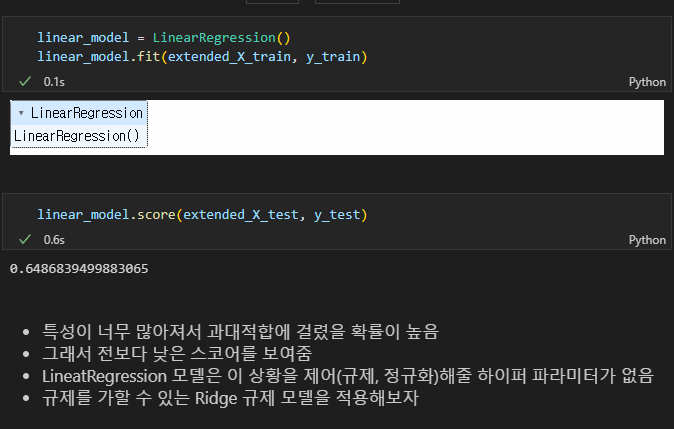
훈련셋의 성능은 높으나 테스트셋의 성능은 떨어짐 : 과대적합


원본데이터가 바뀌어도 데이터가 변하지않은채 복사한 값을 유지하는 copy 함수


훈련셋 데이터의 특성확장을 위해 X_train를 .copy()해옴
복사해온 데이터 boston_copy에
훈련셋 데이터의 정답 y_train을 ['price']라는 이름의 컬럼으로 생성함
data명.info()
: 데이터의 총 건 / 타입 / 결측치 / 전체적인 정보 등을 확인

data명.corr()['특정컬럼명']
특정 컬럼에 대해서만 인덱싱해서 상관관계를 확인
(-1이나 1에 가까울수록 상관도가 높고, 0에 가까울수록 상관도가 낮음)
.abs()로 절대값으로 바꿔준후 sort_values(ascending = False) 로 내림차순 정리

LSTAT 컬럼과 RM컬럼 두 컬럼이 target과 상관관계가 높았으므로
두 컬럼에 대해 특성확장을 해줄것임
특성확장 전 상태 확인을 위해 linear 모델 객체를 생성하고
model.,fit(훈련셋의 'LSTAT' , 훈련셋의 답)으로 학습시키고
linear_model.predict(훈련셋의 'LSTAT") 으로 예측해줌
각각의 컬럼은 1차원자료 Series 이므로 [ ] 안에 한번 더 담아
2차원화 해주고 문제데이터에 담아준다
이후 plt.scatter 산포도 그래프로
그래프 한개는 LSTA컬럼으로 예측한 값,
한개는 실제 정답으로 만들어 얼마나 겹치는지 시각화해본다

LSTAT를 제곱한 값을 새로운 컬럼으로 생성해주고
해당값을 model.fit(문제데이터, 정답데이터)로 학습시킬때
문제데이터에 원래 집어넣었던 LSTAT과 함께
LSTAT X LSTAT도 같이 문제데이터로 넣어준다
에측도 마찬가지로 두 데이터를 같이 예측해주고
이 값을 plt.scatter 산포도그래프로 다시 시각화해서 비교해본다

특성확장한 데이터를 test 셋에도 추가해주고
모델 성능을 다시 확인해보니 모델성능이 상승함

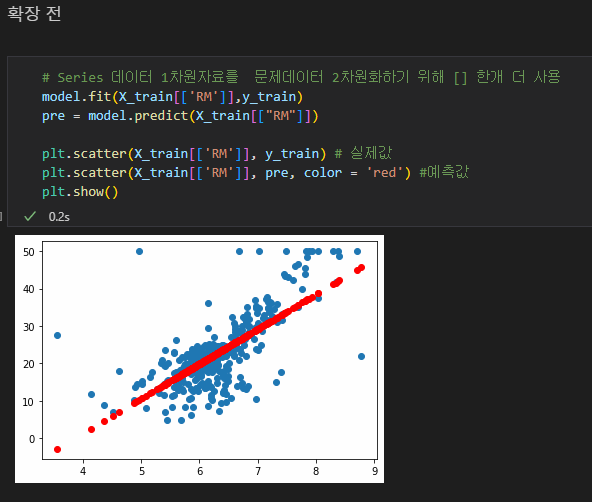


두번째로 상관관계가 높았던 RM 컬럼도 똑같이 특성확장해준 모습